Jupyter Notebook reinforcement learning
A reinforcement learning project where a Q-table is trained to play Tic-Tac-Toe at an almost perfect level.
Project Overview
This project was built in Jupyter Notebook with a reinforcement learning algorithm to train a Q-table. The algorithm learns to play Tic-Tac-Toe efficiently and gradually approaches an optimal strategy. The learning process was visualized over time as the model went through more training iterations and played against a perfect policy.
Technologies
- Jupyter Notebook - Used as the development environment to run and test the model.
- Python - Implemented reinforcement learning algorithm.
- Q-learning - The method used to train the AI to play Tic-Tac-Toe optimally.
- Matplotlib - Visualized the learning process over time.
Learning
RandomPolicy vs trainedPolicy
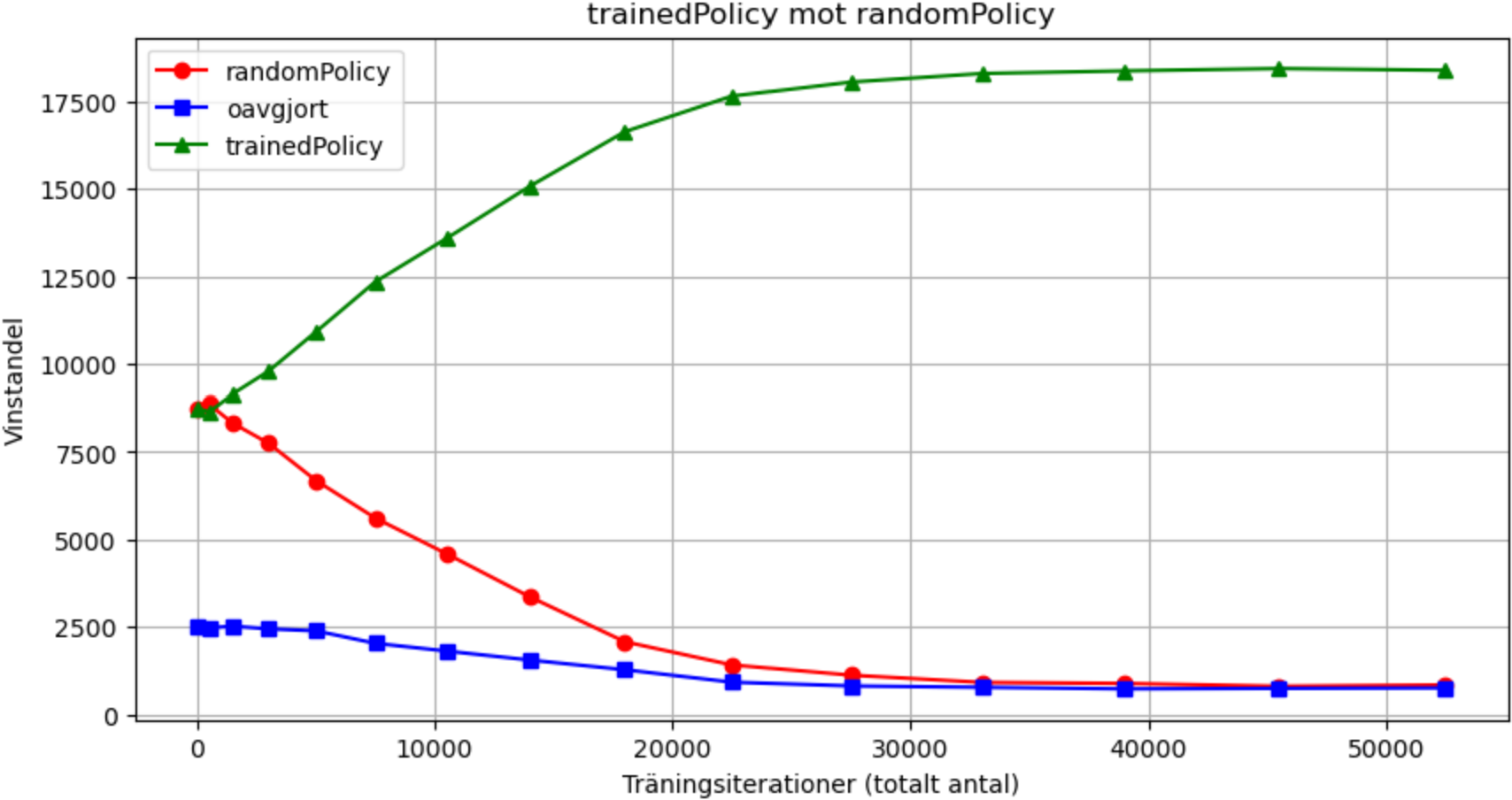
The graph shows how our Q-table learns to play against a Q-table filled with random values. The performance is equally good at the beginning because both contain completely random numbers, but you can see how the policy that learns improves over time.
PerfectPolicy vs trainedPolicy
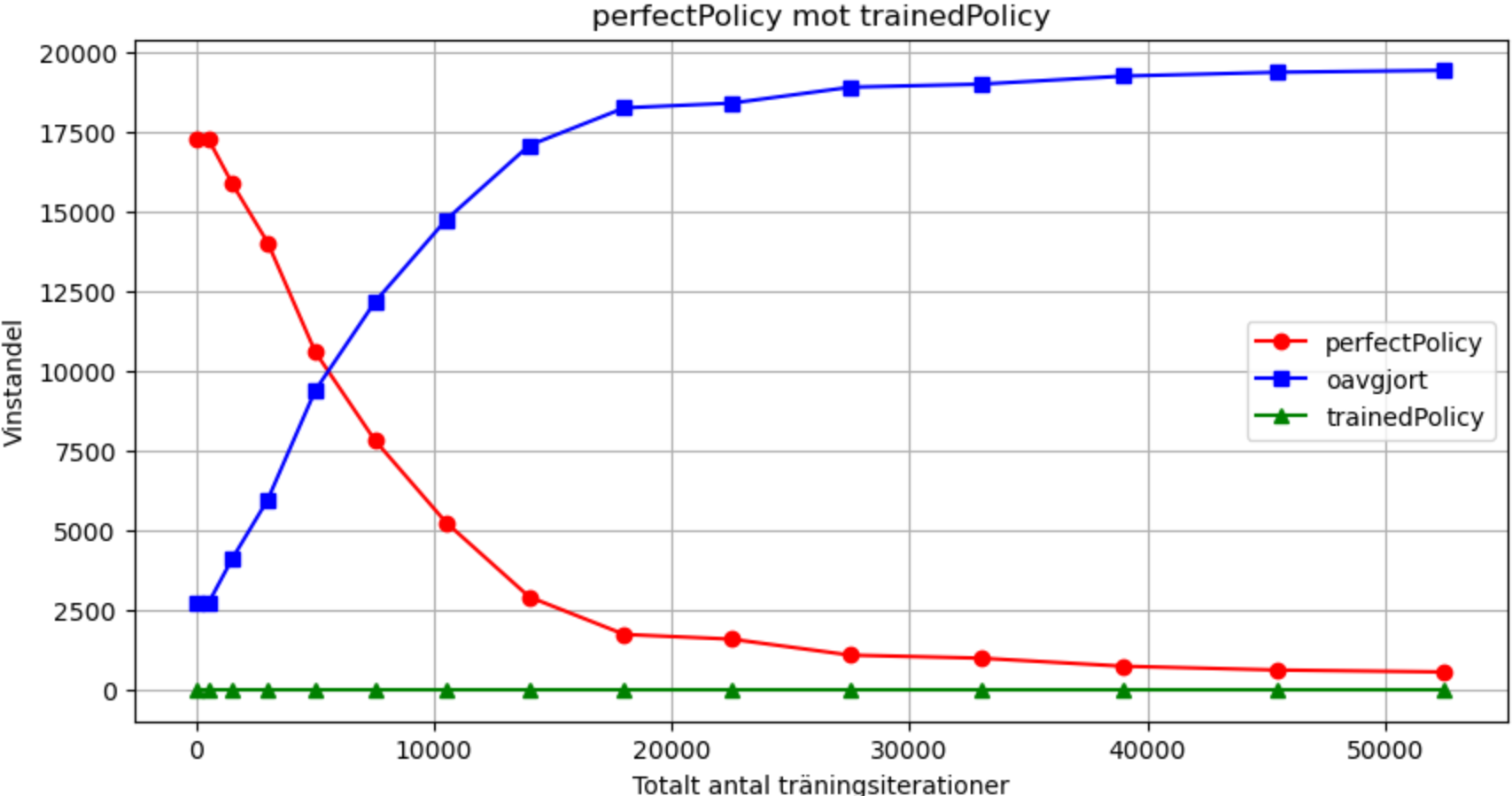
Above you can see how trainedPolicy never wins against PerfectPolicy. However, with more training iterations it gets better and better at getting a draw in the match, because its actions become more similar to PerfectPolicy's actions.
Challenges & Solutions
Understanding the Q-table
One challenge was to truly understand how the policy table's structure was built and how it learns to play better over time. I solved this by diving deep into the data structures at a deep level and using many debug functions to see how the values change.
Balance in Complexity
Finding the balance between appropriate complexity for the project and good performance was something I needed to think about. I therefore chose a simpler reinforcement algorithm that did not use any machine learning libraries. Through this, the code relativt enkel att förstå och prestandan bra. I framtida projekt, eller för storre projekt hade bibliotek som tensorflow varit väldigt intressanta.
Results & Lessons
The project provided deeper insights into reinforcement learning and Q-tables. I developed a better understanding of how more complicated data structures can be built and used for learning algorithms and improved my ability to debug and optimize models.